みなさんこんにちは。
本日は自分で話した内容をテキストにすることに挑戦してみます。
これを実現するには今回取り上げるGCPやIBM Cloudなどがあります。
それでは前者をやってみます。
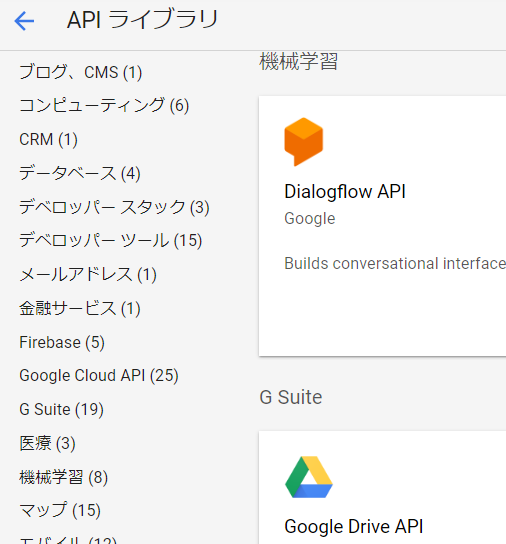
GCPのナビゲーションメニューからAPIとサービス→ライブラリと進みます。カテゴリから機械学習をクリックしCloud Speech-to-Text APIを探しましょう。
見つけたらクリックして次の画面で「有効にする」ボタンにて有効にします。
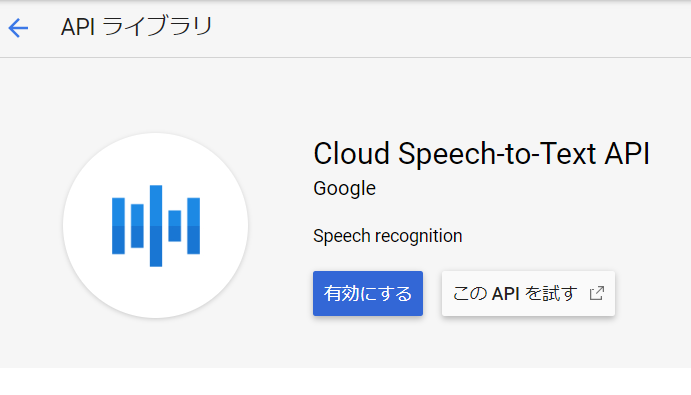
この API を使用するには、認証情報が必要になる可能性があります。開始するには、[認証情報を作成] をクリックしてください。
と注意がでたら「認証情報の作成」ボタンをクリックして次の画面に進みます。

プロジェクトへの認証情報の追加をする作業に入ります。サービスアカウントを作成するのでそのリンクをクリックします。
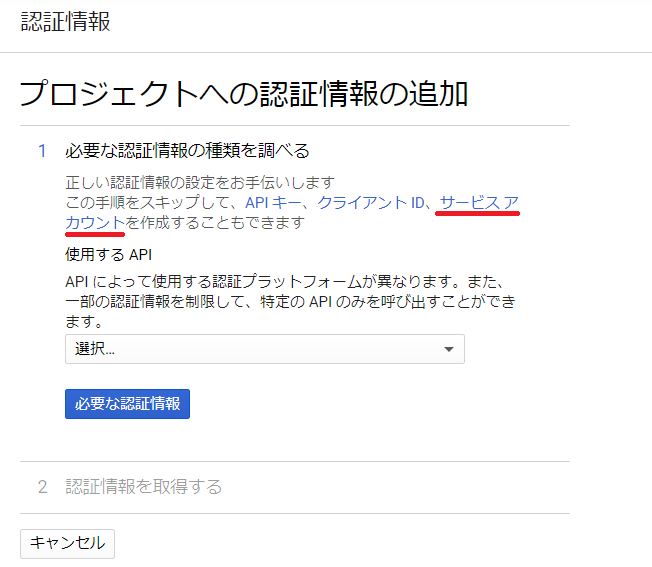
次の画面にてサービスアカウントを作成したらこのアカウントの右の方にある操作にて鍵を作成をします。
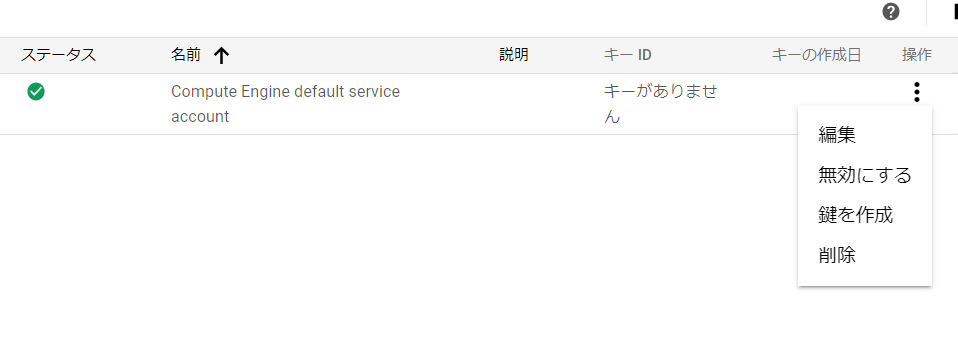
キータイプはJSONとP12があるが前者が推奨となっていたのでこれを作成します。ダウンロードするので任意の場所に保存しておきます。
gcloudツールを使用してSpeech-to-Textに音声文字変換リクエストを送信するためgcloudツールをダウンロードしてGoogle Cloud SDK認証を完了させておきましょう。web検索(gcloudツール)にてすぐ見つかります。
実際に音声をテキストにする挙動を確認します。
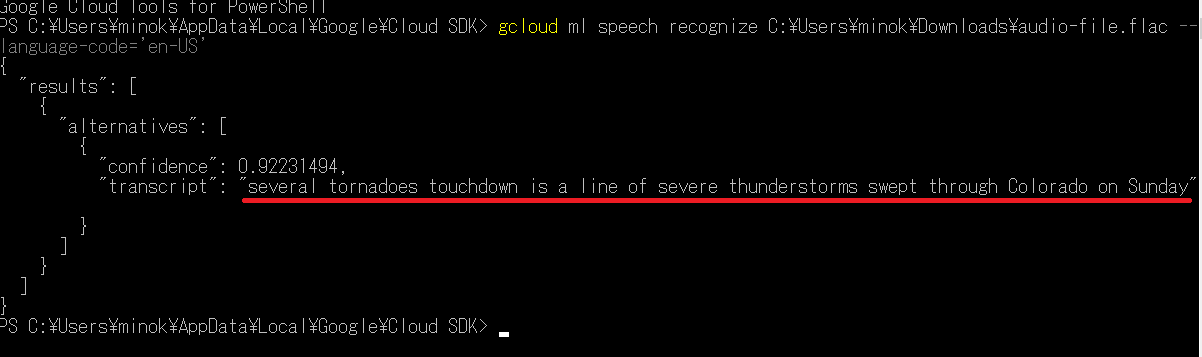
gcloudツールで下記のコマンドを入力します。例はファイルaudio-file.flacが英語の音声になっておりますので言語はen-USで大丈夫ですが日本語ならja-JPにしましょう。IBM Cloudにて同じ部類のSpeech to Textを試したときに入手したファイルです。このファイルはコマンドのようにローカル(自分のパソコン)にありパスを指定してます。同期音声認識といいます。
gcloud ml speech recognize C:\Users\minok\Downloads\audio-file.flac --language-code='en-US'テキストになりました。
今度はリモートファイルの同期音声認識の実行をします。
ファイルがgs://cloud-samples-tests/speech/brooklyn.flacに存在しているという前提です。Google Cloud Storage URLなのでストレージを作成すれば可能です。
gcloud ml speech recognize ‘gs://cloud-samples-tests/speech/brooklyn.flac’ –language-code=’en-US’

前例は音声が短い場合ですが長い場合はどうなのでしょうか?
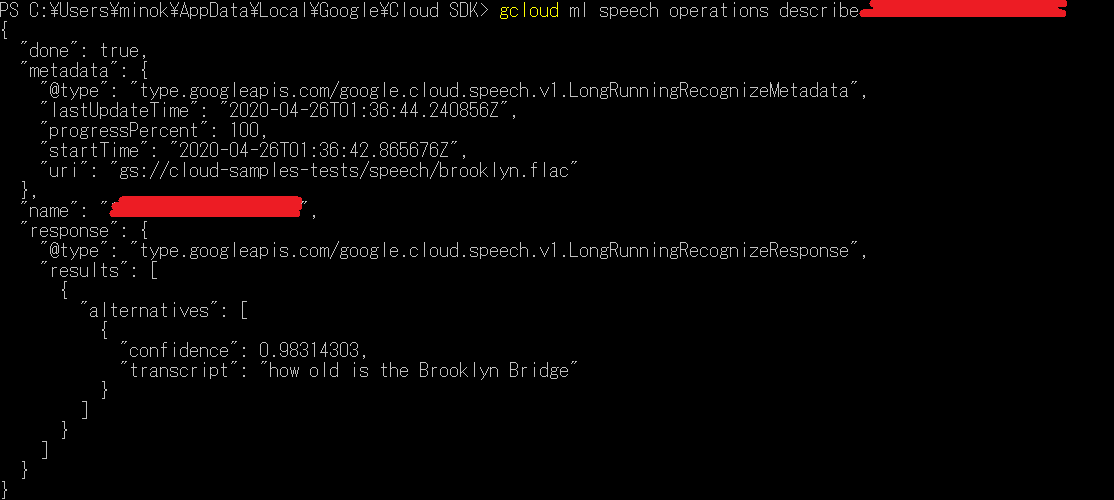
gcloud ml speech recognize-long-running 'gs://cloud-samples-tests/speech/brooklyn.flac' --language-code='en-US' --asyncにてリクエストが成功するとサーバーは長時間実行オペレーションのIDをJSON 形式で返します。下が上記のコマンドを実行したスクショで何かしら数値だけのオペレーションのIDが表示されました。

このオペレーションIDを使用してコマンドを実行します。
gcloud ml speech operations describe OPERATION_ID
または
gcloud ml speech operations wait OPERATION_IDうまくテキストになってます。
マイクからの入力など、ストリーミングの音声を文字に変換することもできますがこちらはgcloudツールの記述はなくC#、Go、Node.js、PHP、Rubyで可能みたいです。これらに関してはまた調査して記載したいと思います。

コメント