「WhisperSpeech」とは、テキストから音声を合成するためのオープンソースのテキスト・トゥ・スピーチ(TTS)システムです。このシステムは、テキストデータを人の声に似た音声に変換する技術を提供します。以下に、WhisperSpeechについて詳しく説明します。
WhisperSpeechの概要
- テキスト・トゥ・スピーチ(TTS)システム: テキストデータを合成音声に変換します。これにより、書かれたテキストを音声で聞くことができます。
- オープンソース: ソースコードが公開されており、誰でも利用、改良、配布することができます。
- 多言語対応: 複数の言語に対応している可能性があります。というのも今後、対応する予定があるとの趣旨が・・・。これにより、異なる言語のテキストを音声に変換することが可能です。
- 高品質な音声合成: 人間の声に近い自然な音声を生成することを目指しています。
アプリケーション例
- オーディオブックの作成: 書籍やドキュメントのテキストを音声に変換し、視覚障害のある人や読書が難しい人のためのオーディオブックを作成できます。
- アシスタントデバイス: 音声アシスタントや対話型システムでの使用。
- 言語学習支援: 言語学習者がテキストの正しい発音を聞くのに役立ちます。
ファイル内容の説明
GitHubには、WhisperSpeechプロジェクトのコード、ドキュメント、および関連リソースが含まれています。
具体的には、以下のような内容が含まれている可能性があります。しっかりと見ていないため。
- ソースコード: Pythonで書かれたTTSシステムの実装。
- ドキュメント: システムの使い方やセットアップに関する指示。
- 例示用のノートブック: 実際にシステムを使用する方法を示すJupyterノートブック。
WhisperSpeechの詳細な内容や使い方については、プロジェクトのREADMEファイルや公式ドキュメントを参照してください。これにより、システムの機能やセットアップ方法についてより詳細な理解を得ることができます。
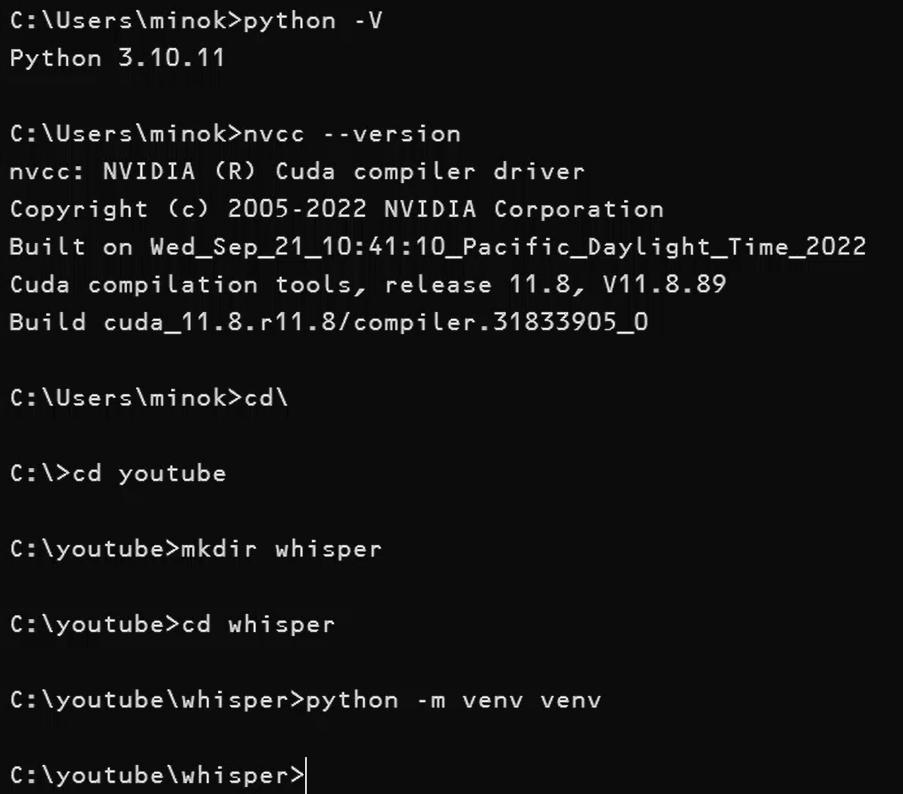
それでは実際にインストールを進めていきましょう。
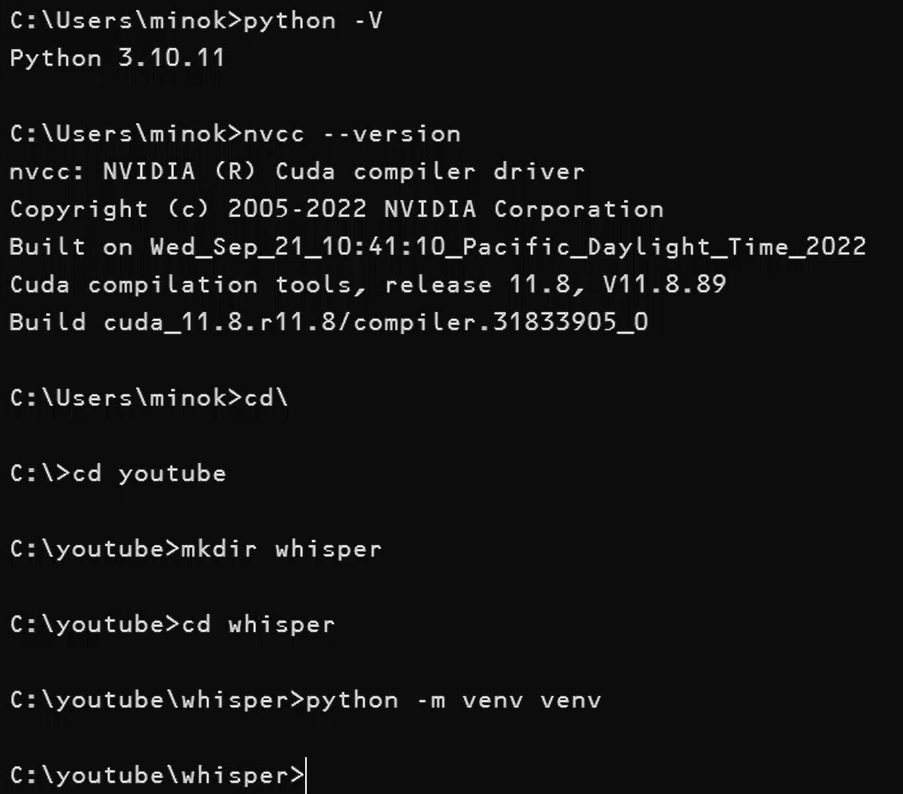
自分のWindowsパソコンにはにCUDA 11.8とPython 3.10(python -Vで確認)がインストールされています。Pythonの仮想環境を作成し、その中に必要なライブラリをインストールすることで、PCのシステム環境を保護しながらプロジェクトを実行できます。
ホストシステムと仮想環境内で使用するCUDAのバージョンを合わせることは重要です。特に、CUDAを利用するアプリケーションやライブラリ(例えばPyTorch)を使用する場合、CUDAのバージョンの互換性が非常に重要になります。
互換性の重要性
- PyTorchとCUDA: PyTorchは特定のCUDAバージョンに対してビルドされています。例えば、CUDA 11.8用のPyTorchは、ホストシステムにもCUDA 11.8がインストールされている必要があります。
- ドライバーとの互換性: CUDAのバージョンは、使用しているGPUドライバーとも互換性がある必要があります。ドライバーが古い場合、新しいバージョンのCUDAをサポートしない可能性があります。
CUDAのバージョン確認
- ホストシステムのCUDAバージョン: ホストシステムで
nvcc --versionコマンドを実行することで、インストールされているCUDAのバージョンを確認できます。 - PyTorchのCUDAバージョン: PyTorchをインストールする際、互換性のあるCUDAバージョンを選択する必要があります。PyTorchのウェブサイトで、システムに適したバージョンを選択できます。
仮想環境の設定
- 仮想環境でのCUDA: 仮想環境内でPyTorchをインストールする際、ホストシステムのCUDAバージョンに合ったPyTorchバージョンを選ぶ必要があります。
CUDAのバージョン不一致は、予期しないエラーや互換性の問題を引き起こす可能性があるため、この点に注意します。もしPyTorchや他のCUDA依存ライブラリを使用する際に問題が発生した場合は、バージョンの確認と一致を最初のトラブルシューティングのステップとして行うと良いでしょう。
以下はその手順です。
- Pythonの仮想環境の作成:
- コマンドプロンプトまたはPowerShellを開きます。
- 適切なディレクトリに移動します(例:
cd プロジェクトのディレクトリ)。 python -m venv venvコマンドを使用して仮想環境を作成します。ここでvenvは仮想環境の名前ですが、任意の名前を使用できます(例:python -m venvwhisper)。
実際ンコマンド(Cドライブ直下にある既存のyoutubeディレクトリに移動し、そこに新規でwhisperディレクトリを作成。そしてwhisperディレクトリに移動後、仮想環境を作成)。
cd\
cd youtube
mkdir whisper
cd whisperpython -m venv venv
- 仮想環境のアクティベート:
- Windowsの場合、仮想環境をアクティベートするには
venv\Scripts\activateコマンドを実行します。
- Windowsの場合、仮想環境をアクティベートするには
- 必要なライブラリのインストール:
- 仮想環境内で
pip install WhisperSpeechのように必要なライブラリをインストールします。CUDAに対応したPyTorchのバージョンをインストールする必要があります。以下のページでコマンドを確認できます。
https://pytorch.org/
今の環境だと下記になります。PyTorchを先にインストールしたほうがいいです。
pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118pip install WhisperSpeechpip install WhisperSpeechコマンドが存在するということは、WhisperSpeechという名前のパッケージが Python Package Index (PyPI) に公開されているという意味です。これにより、pipコマンドを使用してこのパッケージをインストールできます。 - CUDA 11.8に対応したPyTorch、TorchVision、およびTorchAudioをインストールするためのものです。このコマンドは、CUDAをサポートするGPUを持つシステム用のPyTorch関連パッケージをインストールする際に適切です。
torchはPyTorchのメインライブラリです。torchvisionは画像処理に関連する機能を提供します。torchaudioはオーディオ処理に関連する機能を提供します。- 仮想環境内でこのコマンドを実行することで、CUDAに対応したPyTorchの環境をセットアップできます。CUDAをサポートするGPUを搭載している場合、これでWhisperSpeechのスクリプトを実行するための環境が整うはずです。
- 仮想環境内で
- プロジェクトの実行:
- 仮想環境内で、プロジェクトのコードやノートブックを実行します。
この手順により、プロジェクトの実行環境がPCのメインシステムから分離され、環境の汚染を防ぐことができます。また、仮想環境は必要に応じて簡単に削除することができるため、後でクリーンアップするのも簡単です。
WhisperSpeechのようなプロジェクトは、PyPIに登録されていれば、pip installコマンドだけでインストールできます。- ソースコードのクローンが必要なのは、プロジェクトに直接貢献したい場合や、
setup.pyを使ったカスタムインストールが必要な場合です。
仮想環境内でライブラリやCUDAに対応したPyTorchをインストールしたら、メモ帳などで以下を以下を記述します。これを「test.py」として、フォルダwhisperに保存します。
from whisperspeech.pipeline import Pipeline
import torchaudio
# Pipelineの初期化
pipe = Pipeline(s2a_ref='collabora/whisperspeech:s2a-q4-tiny-en+pl.model')
# テキストを音声に変換(ここで正しいメソッドを使用する)
# 例えば `generate` メソッドがあると仮定(実際のメソッド名を確認してください)
result = pipe.generate("""
This is the first demo of Whisper Speech, a fully open source text-to-speech model trained by Collabora and Lion on the Juwels supercomputer.
""")
# CUDAテンソルをCPUに移動(GPU上のテンソルの場合)
result = result.cpu()
# 音声データをWAVファイルとして保存
torchaudio.save('output.wav', result, sample_rate=22050)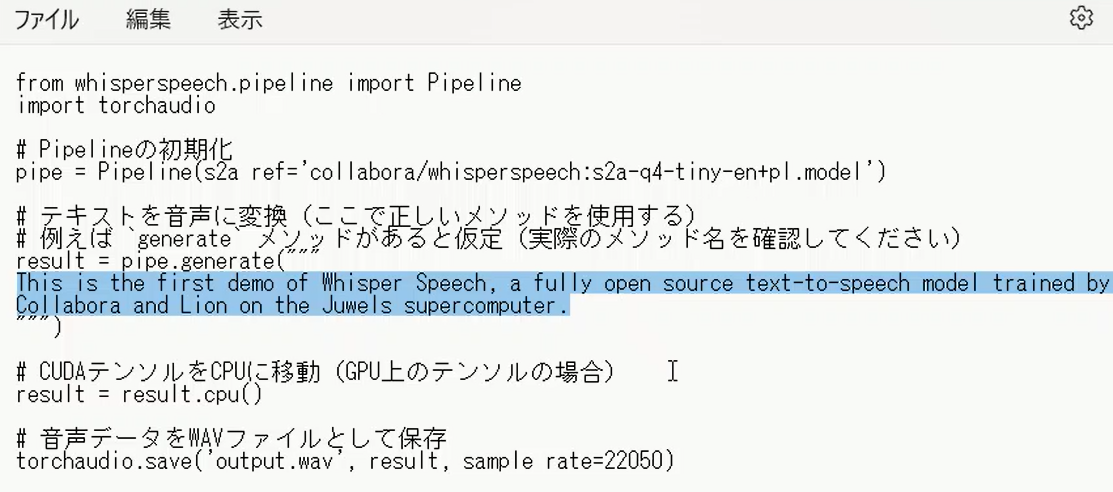
このスクリプトでは、whisperspeech ライブラリを使用してテキストから音声を合成し、その結果をWAVファイルとして保存しています。このプロセスは以下のステップで構成されています。
Pipelineオブジェクトの初期化。pipe.generateメソッドを用いてテキストから音声データ(テンソル)を生成。- 生成されたテンソルをCPUに移動(GPUを使用している場合)。
torchaudio.saveを使って音声データをWAVファイルとして保存。
仮想環境でこのスクリプトを実行します。
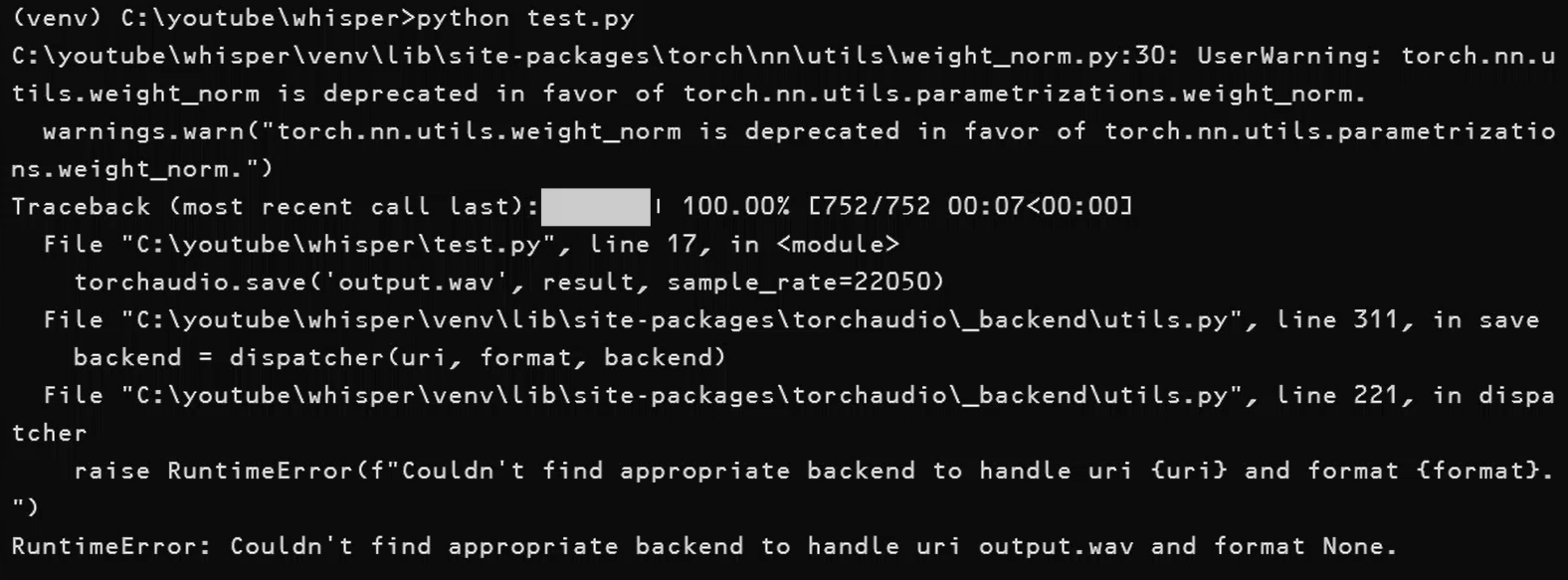
python test.pyしかし、エラーが発生しました。
(venv) C:\youtube\whisper>python test.py
C:\youtube\whisper\venv\lib\site-packages\torch\nn\utils\weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn(“torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.”)
Traceback (most recent call last):███████| 100.00% [752/752 00:07<00:00] File “C:\youtube\whisper\test.py”, line 17, in
torchaudio.save(‘output.wav’, result, sample_rate=22050)
File “C:\youtube\whisper\venv\lib\site-packages\torchaudio_backend\utils.py”, line 311, in save
backend = dispatcher(uri, format, backend)
File “C:\youtube\whisper\venv\lib\site-packages\torchaudio_backend\utils.py”, line 221, in dispatcher
raise RuntimeError(f”Couldn’t find appropriate backend to handle uri {uri} and format {format}.”)
RuntimeError: Couldn’t find appropriate backend to handle uri output.wav and format None.
エラーに対処します。
エラー RuntimeError: Couldn't find appropriate backend to handle uri output.wav and format None. は、torchaudio.save 関数が output.wav ファイルを保存するのに適切なバックエンドを見つけられなかったことを示しています。これは通常、必要なオーディオバックエンドがインストールまたは構成されていない場合に発生します。
この問題を解決するには、以下の手順を試します。
- 必要な依存関係の確認:
torchaudioが必要とする依存関係が適切にインストールされているか確認します。特に、soundfileやsoxなどのライブラリが必要になる場合があります。- これらのライブラリは、
pip install soundfile soxのようなコマンドでインストールできます。
- 異なるファイル形式の試行:
torchaudio.save関数で異なるファイル形式(例:output.mp3)を試してみてください。
- PyTorchとTorchAudioのバージョン確認:
- 使用しているPyTorchとTorchAudioのバージョンが互換性があることを確認してください。不一致がある場合は、互換性のあるバージョンにアップデートする必要があります。
- バックエンドの明示的な指定:
torchaudioのバックエンドを明示的に指定することで、この問題を解決できる場合があります。例えば、torchaudio.set_audio_backend('soundfile')のようにしてみてください。
pip install soundfile soxにて解決できました。インストール後にスクリプトを実行すると音声ファイルが作成されています。

次に音声クローニングを試してみます。
Jupyterノートブックを使用するのですが、これは特にインタラクティブなデータ分析や機械学習、そして今回のような音声処理プロジェクトにおいて非常に良い選択です。JupyterノートブックはPythonコードの実行、結果の可視化、ドキュメント作成を一箇所で行えるため、多くの科学計算やデータサイエンスプロジェクトで好んで使われます。
ジュピターノートブックの特徴
- インタラクティブなコーディング:
- セル単位でコードを実行し、結果を即座に確認できます。これにより、実験やデータ分析を段階的に進めることができます。
- リッチテキストサポート:
- マークダウンやHTMLを使用して、説明文、数式、画像などを含めたドキュメントを作成できます。
- データの視覚化:
- データの図表化やグラフの描画を簡単に行えます。Matplotlib、Seaborn、Plotlyなどのライブラリと組み合わせて使用されます。
- 多言語サポート:
- Python以外にも、R、Julia、Scalaなど複数のプログラミング言語をサポートしています。
- 共有と再現性:
- ノートブックは、コード、データ、図表、説明文が一体化された形式で保存されるため、結果の共有や再現が容易です。
用途
- 教育: 学習教材の作成、授業やワークショップでの使用に適しています。
- データ分析: データの探索的分析、前処理、視覚化に役立ちます。
- 研究: 研究結果の記録、論文への図表生成、分析過程の共有に有用です。
- 機械学習: モデルのプロトタイピング、パラメータチューニング、結果の視覚化に活用できます。
ジュピターノートブックは、その柔軟性と機能性から、多くの科学者、研究者、データアナリスト、教育者にとって貴重なツールとなっています。
Jupyterノートブックは仮想環境内でインストールできます。
pip install notebookJupyterノートブックの起動:
- インストール後、
jupyter notebookコマンドを実行してノートブックを起動します。これによりブラウザが開き、ノートブックのインターフェースが表示されます。
Jupyterノートブックでのスクリプト実行方法
- ノートブックを作成または開く:
- Jupyterノートブックのインターフェースで「New」(新規)をクリックし、新しいノートブックを作成するか、既存のノートブックを開きます。
- コードの記述:
- ノートブック内のセルにPythonコードを記述します。例えば、WhisperSpeechの音声合成のコードをセルに入力します。
- コードの実行:
- コードを含むセルを選択し、ツールバーの「Run」ボタンをクリックするか、キーボードショートカット(通常はShift + Enter)を使用してコードを実行します。
- 結果の確認:
- コードの実行結果は、直接そのセルの下に表示されます。これにはテキスト出力、グラフィックス、音声ファイルの再生などが含まれます。
- ドキュメントの保存:
- 作業が終わったら、ノートブックを保存します。ツールバーの「Save」ボタンを使用して保存できます。
まずは手始めに、GPU使用の確認をJupyterノートブックで行います。
- PyTorchでGPUが利用可能かどうかを確認するために、PythonシェルまたはJupyterノートブックで以下のコードを実行します。
import torchprint(torch.cuda.is_available())- このコマンドが
Trueを返せば、PyTorchはGPUを使用できる状態です。
- このコマンドが
- 使用可能なGPUの詳細を確認するには
import torchprint(torch.cuda.get_device_name(0))
これらのステップに従って、PyTorchがホストのGPUを使用しているかどうかを確認できます。
音声クローニングでは、以下がコードの例です。
from whisperspeech.pipeline import Pipeline
pipe = Pipeline()
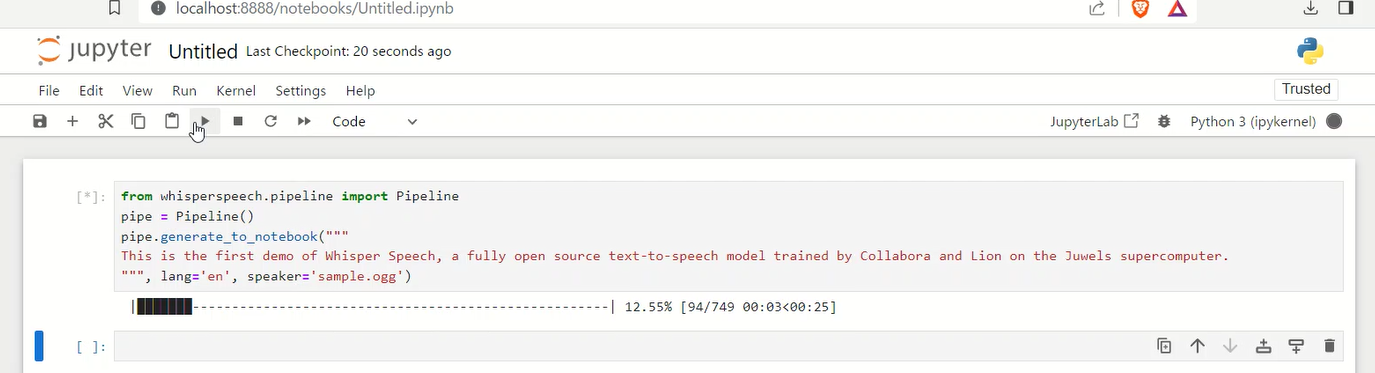
pipe.generate_to_notebook("""
This is the first demo of Whisper Speech, a fully open source text-to-speech model trained by Collabora and Lion on the Juwels supercomputer.
""", lang='en', speaker='https://upload.wikimedia.org/wikipedia/commons/7/75/Winston_Churchill_-_Be_Ye_Men_of_Valour.ogg')スクリプトでは、WhisperSpeech ライブラリの Pipeline オブジェクトを使用して、指定されたテキストを音声に変換しています。このプロセスでは、lang='en' で英語の音声モデルが使用され、speaker='path/to/downloaded/file.ogg' で指定された参照音声(ローカルファイル)に基づいて音声が生成されています。
ブラウザにて、コードを保存して実行すると以下のようなエラーが発生しました。
C:\youtube\whisper\venv\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm C:\youtube\whisper\venv\lib\site-packages\fastprogress\fastprogress.py:107: UserWarning: Couldn’t import ipywidgets properly, progress bar will use console behavior warn(“Couldn’t import ipywidgets properly, progress bar will use console behavior”) C:\youtube\whisper\venv\lib\site-packages\torch\nn\utils\weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm. warnings.warn(“torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.”) The torchaudio backend is switched to ‘soundfile’. Note that ‘sox_io’ is not supported on Windows. C:\youtube\whisper\venv\lib\site-packages\speechbrain\utils\torch_audio_backend.py:22: UserWarning: torchaudio._backend.set_audio_backend has been deprecated. With dispatcher enabled, this function is no-op. You can remove the function call. torchaudio.set_audio_backend(“soundfile”) The torchaudio backend is switched to ‘soundfile’. Note that ‘sox_io’ is not supported on Windows. C:\youtube\whisper\venv\lib\site-packages\speechbrain\utils\torch_audio_backend.py:22: UserWarning: torchaudio._backend.set_audio_backend has been deprecated. With dispatcher enabled, this function is no-op. You can remove the function call. torchaudio.set_audio_backend(“soundfile”)
—————————————————————————OSError Traceback (most recent call last) Cell In[3], line 3 1 fromwhisperspeech.pipelineimport Pipeline 2 pipe = Pipeline() —-> 3 pipe.generate_to_notebook(“”” 4 This is the first demo of Whisper Speech, a fully open source text-to-speech model trained by Collabora and Lion on the Juwels supercomputer. 5 “””, lang=’en’, speaker=’https://upload.wikimedia.org/wikipedia/commons/7/75/Winston_Churchill_-_Be_Ye_Men_of_Valour.ogg‘) File C:\youtube\whisper\venv\lib\site-packages\whisperspeech\pipeline.py:93, in Pipeline.generate_to_notebook(self, text, speaker, lang, cps, step_callback) 92 def generate_to_notebook(self, text, speaker=None, lang=’en’, cps=15, step_callback=None): —> 93 self.vocoder.decode_to_notebook(self.generate_atoks(text, speaker, lang=lang, cps=cps, step_callback=None)) File C:\youtube\whisper\venv\lib\site-packages\whisperspeech\pipeline.py:80, in Pipeline.generate_atoks(self, text, speaker, lang, cps, step_callback) 78 def generate_atoks(self, text, speaker=None, lang=’en’, cps=15, step_callback=None): 79 if speaker isNone: speaker = self.default_speaker —> 80elif isinstance(speaker, (str, Path)): speaker = self.extract_spk_emb(speaker) 81 text = text.replace(“\n“, ” “) 82 stoks = self.t2s.generate(text, cps=cps, lang=lang, step=step_callback) File C:\youtube\whisper\venv\lib\site-packages\whisperspeech\pipeline.py:70, in Pipeline.extract_spk_emb(self, fname) 68 if self.encoder isNone: 69 fromspeechbrain.pretrainedimport EncoderClassifier —> 70 self.encoder = EncoderClassifier.from_hparams(“speechbrain/spkrec-ecapa-voxceleb”, 71 savedir=”~/.cache/speechbrain/”, 72 run_opts={“device”: “cuda”}) 73 samples, sr = torchaudio.load(fname) 74 samples = self.encoder.audio_normalizer(samples[0,:30*sr], sr) File C:\youtube\whisper\venv\lib\site-packages\speechbrain\pretrained\interfaces.py:467, in Pretrained.from_hparams(cls, source, hparams_file, pymodule_file, overrides, savedir, use_auth_token, revision, download_only, **kwargs) 465 clsname = cls.__name__ 466 savedir = f”./pretrained_models/{clsname}–{hashlib.md5(source.encode(‘UTF-8′, errors=’replace’)).hexdigest()}” –> 467 hparams_local_path = fetch( 468 filename=hparams_file, 469 source=source, 470 savedir=savedir, 471 overwrite=False, 472 save_filename=None, 473 use_auth_token=use_auth_token, 474 revision=revision, 475 ) 476 try: 477 pymodule_local_path = fetch( 478 filename=pymodule_file, 479 source=source, (…) 484 revision=revision, 485 ) File C:\youtube\whisper\venv\lib\site-packages\speechbrain\pretrained\fetching.py:181, in fetch(filename, source, savedir, overwrite, save_filename, use_auth_token, revision, cache_dir, silent_local_fetch) 179 sourcepath = pathlib.Path(fetched_file).absolute() 180 _missing_ok_unlink(destination) –> 181 destination.symlink_to(sourcepath) 182 return destination File ~\AppData\Local\Programs\Python\Python310\lib\pathlib.py:1255, in Path.symlink_to(self, target, target_is_directory) 1250 def symlink_to(self, target, target_is_directory=False): 1251 “”” 1252 Make this path a symlink pointing to the target path. 1253 Note the order of arguments (link, target) is the reverse of os.symlink. 1254 “”” -> 1255 self._accessor.symlink(target, self, target_is_directory) OSError: [WinError 1314] クライアントは要求された特権を保有していません。: ‘C:\\Users\\minok\\.cache\\huggingface\\hub\\models–speechbrain–spkrec-ecapa-voxceleb\\snapshots\\5c0be3875fda05e81f3c004ed8c7c06be308de1e\\hyperparams.yaml’ -> ‘~\\.cache\\speechbrain\\hyperparams.yaml’
原因の調査。
表示されている OSError: [WinError 1314] は、Windowsでシンボリックリンクを作成するための特権が不足していることを示しています。このエラーは、speechbrain ライブラリが必要なファイルをダウンロードし、キャッシュディレクトリにシンボリックリンクを作成しようとした際に発生しています。
試した解決策
- Windowsでコマンドプロンプトを「管理者として実行」し、その中で
jupyter notebookコマンドを実行してみます。
仮想環境はすでに作成しているので、目的のディレクトリに移動して仮想環境をアクティベートします。
cd\
cd youtube
cd whisper
venv\Scripts\activate
ブラウザで先のコードを実行します。しかし、エラーは出たものの内容が変わりました。
LibsndfileError Traceback (most recent call last) Cell In[2], line 3 1 fromwhisperspeech.pipelineimport Pipeline 2 pipe = Pipeline() —-> 3 pipe.generate_to_notebook(“”” 4 This is the first demo of Whisper Speech, a fully open source text-to-speech model trained by Collabora and Lion on the Juwels supercomputer. 5 “””, lang=’en’, speaker=’https://upload.wikimedia.org/wikipedia/commons/7/75/Winston_Churchill_-_Be_Ye_Men_of_Valour.ogg‘) File C:\youtube\whisper\venv\lib\site-packages\whisperspeech\pipeline.py:93, in Pipeline.generate_to_notebook(self, text, speaker, lang, cps, step_callback) 92 def generate_to_notebook(self, text, speaker=None, lang=’en’, cps=15, step_callback=None): —> 93 self.vocoder.decode_to_notebook(self.generate_atoks(text, speaker, lang=lang, cps=cps, step_callback=None)) File C:\youtube\whisper\venv\lib\site-packages\whisperspeech\pipeline.py:80, in Pipeline.generate_atoks(self, text, speaker, lang, cps, step_callback) 78 def generate_atoks(self, text, speaker=None, lang=’en’, cps=15, step_callback=None): 79 if speaker isNone: speaker = self.default_speaker —> 80elif isinstance(speaker, (str, Path)): speaker = self.extract_spk_emb(speaker) 81 text = text.replace(“\n“, ” “) 82 stoks = self.t2s.generate(text, cps=cps, lang=lang, step=step_callback) File C:\youtube\whisper\venv\lib\site-packages\whisperspeech\pipeline.py:73, in Pipeline.extract_spk_emb(self, fname) 69 fromspeechbrain.pretrainedimport EncoderClassifier 70 self.encoder = EncoderClassifier.from_hparams(“speechbrain/spkrec-ecapa-voxceleb”, 71 savedir=”~/.cache/speechbrain/”, 72 run_opts={“device”: “cuda”}) —> 73 samples, sr = torchaudio.load(fname) 74 samples = self.encoder.audio_normalizer(samples[0,:30*sr], sr) 75 spk_emb = self.encoder.encode_batch(samples) File C:\youtube\whisper\venv\lib\site-packages\torchaudio\_backend\utils.py:204, in get_load_func.<locals>.load(uri, frame_offset, num_frames, normalize, channels_first, format, buffer_size, backend) 127 “””Load audio data from source. 128 129 By default (“normalize=True“, “channels_first=True“), this function returns Tensor with (…) 201 `[channel, time]` else `[time, channel]`. 202 “”” 203 backend = dispatcher(uri, format, backend) –> 204return backend.load(uri, frame_offset, num_frames, normalize, channels_first, format, buffer_size) File C:\youtube\whisper\venv\lib\site-packages\torchaudio\_backend\soundfile.py:27, in SoundfileBackend.load(uri, frame_offset, num_frames, normalize, channels_first, format, buffer_size) 17 @staticmethod 18 def load( 19 uri: Union[BinaryIO, str, os.PathLike], (…) 25 buffer_size: int = 4096, 26 ) -> Tuple[torch.Tensor, int]: —> 27return soundfile_backend.load(uri, frame_offset, num_frames, normalize, channels_first, format) File C:\youtube\whisper\venv\lib\site-packages\torchaudio\_backend\soundfile_backend.py:221, in load(filepath, frame_offset, num_frames, normalize, channels_first, format) 139 @_requires_soundfile 140 def load( 141 filepath: str, (…) 146 format: Optional[str] = None, 147 ) -> Tuple[torch.Tensor, int]: 148 “””Load audio data from file. 149 150 Note: (…) 219 `[channel, time]` else `[time, channel]`. 220 “”” –> 221with soundfile.SoundFile(filepath, “r”) as file_: 222 if file_.format != “WAV” or normalize: 223 dtype = “float32” File C:\youtube\whisper\venv\lib\site-packages\soundfile.py:658, in SoundFile.__init__(self, file, mode, samplerate, channels, subtype, endian, format, closefd) 655 self._mode = mode 656 self._info = _create_info_struct(file, mode, samplerate, channels, 657 format, subtype, endian) –> 658 self._file = self._open(file, mode_int, closefd) 659 if set(mode).issuperset(‘r+’) and self.seekable(): 660 # Move write position to 0 (like in Python file objects) 661 self.seek(0) File C:\youtube\whisper\venv\lib\site-packages\soundfile.py:1216, in SoundFile._open(self, file, mode_int, closefd) 1213 if file_ptr == _ffi.NULL: 1214 # get the actual error code 1215 err = _snd.sf_error(file_ptr) -> 1216raise LibsndfileError(err, prefix=”Error opening {0!r}: “.format(self.name)) 1217 if mode_int == _snd.SFM_WRITE: 1218 # Due to a bug in libsndfile version <= 1.0.25, frames != 0 1219 # when opening a named pipe in SFM_WRITE mode. 1220 # See http://github.com/erikd/libsndfile/issues/77. 1221 self._info.frames = 0 LibsndfileError: Error opening ‘https://upload.wikimedia.org/wikipedia/commons/7/75/Winston_Churchill_-_Be_Ye_Men_of_Valour.ogg‘: System error.
原因の調査。
表示された LibsndfileError は、torchaudio がリモートURL(この場合はウィンストン・チャーチルのスピーチのURL)から直接音声ファイルを読み込もうとして失敗したことを示しています。torchaudio は、通常、ローカルファイルシステムにある音声ファイルを読み込むように設計されており、URLからの直接読み込みはサポートしていません。
解決策
- 音声ファイルのダウンロード:
- 参照音声として使用したいファイルを手動でダウンロードし、ローカルファイルシステムに保存します。
- ダウンロードしたファイルへのパスの指定:
- ダウンロードした音声ファイルのローカルパスを
speaker引数に指定します。例えば、speaker='downloaded_file.ogg'のように指定します(downloaded_file.oggはダウンロードしたファイルの名前です)。
- ダウンロードした音声ファイルのローカルパスを
- コードの修正:
- Jupyterノートブック内で、
speaker引数を更新して、ダウンロードしたファイルのパスを指定します。なお、コードと同じ場合に音声ファイルがある時は、ファイル名だけを記述します。
- Jupyterノートブック内で、
from whisperspeech.pipeline import Pipeline
# Pipelineオブジェクトの初期化
pipe = Pipeline()
# 以降で pipe.generate_to_notebook(...) を使用
pipe.generate_to_notebook(
"""
This is the first demo of Whisper Speech, a fully open source text-to-speech model trained by Collabora and Lion on the Juwels supercomputer.
""",
lang='en',
speaker='path/to/downloaded/file.ogg'
)