以前、歩み値を保存するスクリプトを紹介しました。
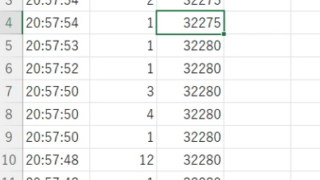
しかし、次のように全く同じ時間に同じ出来高と約定値があると、取りこぼしが発生するという不具合がありました。この場合は時刻14:11:21の時、全く同じ値があります。さらに連続はしていないが、14:11:23の時にも同じデータがあります。
| 14:11:23 | 100 | 9231 |
| 14:11:23 | 1000 | 9231 |
| 14:11:23 | 100 | 9231 |
| 14:11:23 | 500 | 9230 |
| 14:11:23 | 2100 | 9230 |
| 14:11:22 | 100 | 9229 |
| 14:11:21 | 200 | 9229 |
| 14:11:21 | 200 | 9229 |
| 14:11:18 | 100 | 9228 |
これらの全く同じデータも、別扱いして保存できるように修正したつもりです。今回はさらに、データベース(MySQLなど)にも保存できるようにもしました。前半は別のエクセルに保存する方法です。
今回のプロジェクトでは、Pythonを活用してExcelデータの自動処理を実現しました。このスクリプトは、特定のExcelファイルからデータを読み込み、重複を避けつつ新しい情報を追加するための自動化されたプロセスを提供します。ここでは、スクリプトの主な機能について説明します。
- ハッシュ値の生成: 各行のデータからユニークなハッシュ値を生成し、データの一意性を保証します。これにより、同じデータの重複追加を防ぎます。
- リアルタイムデータ処理: スクリプトはExcelファイルが利用可能になるまで待機し、アクセスでき次第データを読み込みます。これにより、リアルタイムでのデータ更新をサポートします。
- データの統合と更新: 新しいユニークなデータが検出されると、スクリプトはそれを既存のJSONファイルに追加し、結果を新しいExcelシートに出力します。このプロセスは、データの整合性を保ちながら情報を最新の状態に保つために重要です。
- 自動化されたループ処理: スクリプトは定期的にデータのチェックを行い、新しい情報があるかどうかを確認します。この自動化されたループにより、手動でのデータ更新作業を削減し、効率を大幅に向上させます。
- ユーザーフィードバック: 新しいデータが追加されるたびに、スクリプトは処理されたデータを表示し、処理の完了をユーザーに知らせます。これにより、プロセスの透明性が確保されます。
使い方
このスクリプトを自分の環境で実行するには、少しの調整が必要です。以下は、スクリプトをカスタマイズして、ニーズに合わせるための簡単なステップです。
- ファイルパスの設定: スクリプト内で、データを読み込むExcelファイルやデータを保存するJSONファイルのパスは、あなたの環境に合わせて指定する必要があります。例えば、
file_pathやjson_file_pathなどの変数を見つけ、それらをあなたのファイルシステムに存在する正確なパスに書き換えてください。 - 実行環境の準備: このスクリプトはPythonで書かれており、実行にはPythonのインストールが必要です。また、
pandasやopenpyxlなどのライブラリも使用していますので、これらがインストールされていない場合は、インストールが必要になります。(例:pip installopenpyxl) - スクリプトの実行: 環境が準備できたら、ターミナルやコマンドプロンプトからスクリプトを実行してください。スクリプトがデータの読み込み、処理、保存を自動的に行います。
- 結果の確認: スクリプトの実行が完了したら、指定した保存先のファイルを開いて、結果を確認してください。新しい情報が正しく追加されているかを確認し、必要に応じて調整を行います。
このスクリプトはエクセルが上書き保存されたタイミングで発動します。それゆえ、VBAで定期的(例えば5秒間隔)に上書き保存するコードを記述します。つまり、一定間隔で上書き保存するマクロを実行すれば歩み値を保存し続けてくれます。エクセルファイルには、必要なVBAマクロが既に組み込まれています。
書き込み先のエクセルファイルとJSONファイルは自動的に作成されます。スクリプト実行中に開けてはいけません。そして監視対象エクセルファイルが上書き保存され、更新データがあれば、書き込み先のエクセルファイルにシートをどんどん作成していきます。シートが複数{上書き保存された回数分(かつデータの更新がある場合)}あり、わかりずらいのは具合が悪いです。そこで、複数のシートを1つにまとめるスクリプトも作成しました。歩み値取り込み後に行うことで、1つのシートにまとめます。
次にデータベースに保存する方法です。こちらは、Claude3の力をかりて、作成してあります。実は、同じようなものをGPT3.5で作成済みであったのですが、同じく取りこぼしがありました。Claude3では5ドル分のクレジットがあったので、質問内容を慎重に吟味して、できるだけ対話が短く済むようにしました。5ドル以内作成することができました。プログラムができなくてもこれくらいならできるようになります。
監視対象のエクセルファイルの内容は同じで、保存先をエクセルファイルからMySQLやMariaDBにしています。データベースサーバーはクラウドに設置してもいいですし、ローカルでもOKです。以前、Google Cloudの無料枠にデータベースを設置する方法を記事にしました。
「データベースとは、大量のデータを効率的に管理・操作するためのシステムです。今回、『MySQL』という種類のデータベースを使用することにしました。『MySQL』は、無料で利用できるデータベースのソフトウェアで、その性能の高さから世界中で広く使われています。
さて、『MySQL』を使うには、通常、サーバーにインストールする必要があります。しかし、もしWindowsを使っている場合でも心配はいりません。Windowsでは直接『MySQL』をインストールすることが難しい場合がありますが、『WSL』というツールを使うことで、Windows上でも『MySQL』をスムーズに動かすことが可能です。
『WSL』は「Windows Subsystem for Linux」の略で、このツールを使うことにより、Windowsの中にLinuxの環境を作り出し、そこで『MySQL』を含むさまざまなLinux用のソフトウェアを動かすことができます。つまり、Windowsを使っていても、『WSL』を介して『MySQL』を設置し、活用することが可能なんです。
この方法により、Windowsのユーザーでも、Linuxの強力な機能やソフトウェアを自由に使うことができるようになります。それにより、データベース管理においても、より柔軟で効率的な作業が実現可能です。」
WSL(Windows Subsystem for Linux)のように、Windows上でLinux環境を利用する方法以外にも、特に開発環境を構築する際に役立つ様々なツールや技術があります。Dockerはその一例で、他にもいくつか選択肢があります。
Docker
- Dockerは、アプリケーションをコンテナと呼ばれる隔離された環境内で実行するためのプラットフォームです。各コンテナにはアプリケーションが動作するのに必要なライブラリや依存関係が含まれており、異なる環境間でのアプリケーションの移植性と一貫性を向上させます。
VirtualBoxやVMware
- VirtualBoxやVMwareなどの仮想化ソフトウェアを使用すると、物理的なハードウェア上に複数の仮想マシン(VM)を作成できます。これらのVMは、実際のコンピュータのように振る舞い、異なるオペレーティングシステムをインストールして実行することができます。
Vagrant
- Vagrantは、仮想マシンの構築、設定、管理を簡素化するツールです。Vagrantを使用すると、開発環境をコードとして定義し、共有することができます。これにより、チームメンバー間での環境の一貫性を保ちながら、設定の手間を大幅に削減できます。
Cloud-based Development Environments
- クラウドベースの開発環境(例:AWS Cloud9、GitHub Codespaces)を使用すると、ローカルマシンに何もインストールせずに、ブラウザから直接アクセスして開発作業を行うことができます。これらのサービスは、リモートサーバ上に開発環境を構築し、インターネットを通じてアクセスを提供します。
Linux Subsystems or Compatibility Layers on Windows
- CygwinやMinGWなど、Windows上でLinuxのような環境を提供するための互換性レイヤーまたはサブシステムもあります。これらのツールは、Windows上でLinux特有のコマンドやプログラムを使いたい場合に役立ちます。
これらのツールや技術は、プロジェクトの要件やチームの好みに応じて選択されます。各ツールには独自の特徴があり、特定の課題を解決するために最適化されています。
使い方
空のデータベースを作成しておきます。スクリプトに自分の環境に合わせて、データベース情報を記入します。ホスト名、データベース名、ユーザー名、パスワードがそれにあたります。テーブルはスクリプトが自動で作成します。また、データベースに記述される情報に時間が2つあります。以下がその理由です。
trade_timeとtimestampの2つの時間列がありますが、それぞれ異なる目的で使用されています。
trade_time: この列は、エクセルファイルから取得した取引の実際の時刻を表します。つまり、取引が行われた実際の日時を示しています。この情報は、取引データの分析や時系列での傾向の把握に役立ちます。timestamp: この列は、データがデータベースに挿入された時刻を自動的に記録します。これは、データベースのデフォルト値としてCURRENT_TIMESTAMPを使用しているため、データが実際にデータベースに保存された日時を示します。この情報は、データの挿入順序や、データベースへの書き込みパフォーマンスの監視に役立ちます。
したがって、両方の列を保持することをお勧めします。trade_timeは取引データの分析に必要であり、timestampはデータベース管理の目的で有用です。
データの確認はWorkbenchが便利です。例として、最新の30行を表示する構文は以下のようになります。
SELECT * FROM trade_data
ORDER BY ID DESC
LIMIT 30;このプロジェクトは、OpenAIの先進的な人工知能技術(ChatGPT)を活用して実現しました。この旅では、データの重複を許容しつつ、時間軸で異なるデータを正確に「まとめ」シートに転記する方法に焦点を当てています。しかし、質問自体がわかっていないと実現はできませので、学習するに越したことはありません。次々に問題が発生するので、その都度対処しました。
この方法は、株式市場の取引データ分析や、同一時間帯に複数のイベントが記録される他の分野でのデータ処理に特に有効です。実際のコーディングプロセスを通じて、データの統合だけでなく、PythonとExcelの強力な連携を示すことができました。
このプロジェクトを通じて、以下の重要な洞察を得ました。
- データの重複を正確に扱うことの重要性
- 自動化による時間の節約と効率化
- OpenAIとの協力による問題解決の力
この成果をYouTubeとブログ記事で共有することで、同じ課題に直面している他の人々に役立つことを願っています。また、今後もこのような自動化技術を探求し、知見を共有することで、コミュニティがさらに成長することを楽しみにしています。
最後になりましたが、このプロジェクトを実現するために協力してくれたOpenAIのChatGPTに感謝の意を表します。人工知能との協業は、未来のデータ処理に新たな可能性をもたらしてくれました。