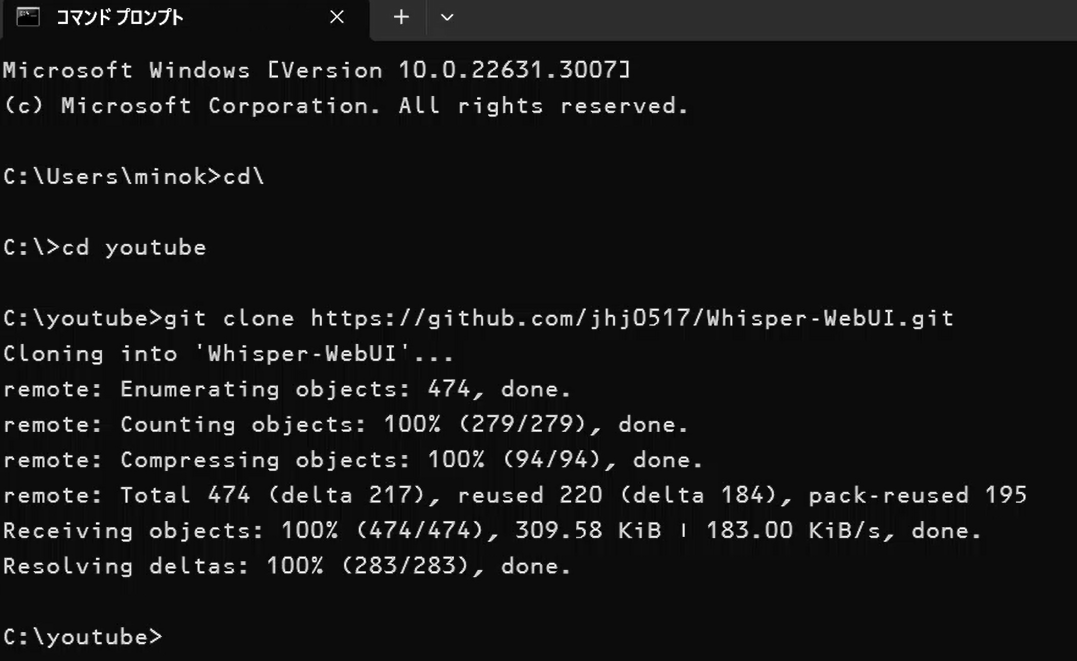
以前、pythonの仮想環境にて、音声クローニングのVALL-E Xを自分のPCにインストールしました。
本日はDockerを使用して、これを実現します。WSL上にDockerをインストールしておきます。
WSL(Windows Subsystem for Linux) は、Windows 10やWindows 11上で直接Linuxオペレーティングシステムを実行するための機能です。これにより、WindowsユーザーはLinuxのコマンドラインツール、ユーティリティ、アプリケーションをWindows環境内で利用できるようになります。以下の点を押さえておくと良いでしょう。
- デュアルブート不要: WSLを使うと、Linuxを別のオペレーティングシステムとしてインストールするためにパソコンを再起動する必要がなくなります。Windows内で直接Linuxが動作します。
- 開発者向けツールの利用: WSLは特に開発者にとって有用です。Linux環境で動作するプログラミング言語やツール、アプリケーションをWindows上で使えるようになります。
- 簡単なセットアップ: WSLはWindowsの機能として組み込まれているため、比較的簡単にセットアップできます。Microsoft StoreからLinuxディストリビューション(例えばUbuntu、Debianなど)をダウンロードして、数ステップでセットアップが完了します。
- ファイルシステムの共有: WindowsとLinuxの間でファイルシステムを共有できるため、両方の環境で同じファイルにアクセスし、作業することができます。
- パフォーマンス: WSLはWindows上で高いパフォーマンスを提供します。特にWSL 2では、Linuxカーネルが直接Windows上で動作するため、パフォーマンスが大幅に向上しました。
簡単に言うと、WSLはWindowsユーザーがLinuxの機能を利用できるようにするための強力なツールです。これにより、WindowsとLinuxの両方の環境で作業することが容易になり、開発者にとって特に便利な機能を提供します。
Dockerを使用することでプロジェクトの依存関係の問題を解決し、より一貫した開発とデプロイメントの環境を提供できます。以下にその主なメリットについて説明します。
- 環境の一貫性と予測可能性: Dockerは「コンテナ」と呼ばれる隔離された環境を提供します。これにより、私が開発した環境がそのまま他の人のマシンでも動作するようになります。これは、依存関係や特定のライブラリのバージョンに起因する問題を減らします。
- ホストシステムからの独立性: Dockerコンテナはホストシステムから隔離されています。これにより、ホストのCUDAバージョンやその他のシステム固有の設定に依存せずに、アプリケーションを実行できます。結果として、異なる環境や異なるCUDAバージョンを持つユーザー間での互換性が向上します。
- セットアップの簡素化: ユーザーはDockerをインストールしてコンテナを起動するだけで、必要なすべての依存関係や設定が含まれた環境を得ることができます。これにより、複雑なセットアップ手順を実行する必要がなくなります。
- 開発と本番環境の整合性: Dockerを使用すると、開発環境と本番環境の違いによって生じる問題を減少させることができます。同じコンテナイメージを開発、テスト、本番環境で使用することで、環境間の差異を最小限に抑えられます。
- スケーラビリティと管理の容易さ: Dockerコンテナは軽量であり、複数のコンテナを簡単に管理・スケールアップすることができます。これにより、大規模なアプリケーションやマイクロサービスの管理が容易になります。
Dockerを使用すると、開発者はシステムの特定の設定や依存関係に煩わされることなく、より一貫性のある環境でプロジェクトに集中できるようになります。また、ユーザーも容易にプロジェクトをセットアップし、実行することができます。
前提条件
WSLにDockerをインストール済みである。
WSLにNVIDIAのコンテナツールキットがインストール済みである。
NVIDIAのコンテナツールキット(NVIDIA Container Toolkit)は、DockerとGPUの統合において非常に重要です。以下にその主なポイントを説明します。
- GPUのサポート: NVIDIAのコンテナツールキットは、Dockerコンテナ内でNVIDIA GPUを直接利用するためのメカニズムを提供します。これにより、GPUを必要とするアプリケーションや機械学習のモデルなどを、コンテナ内で効率的に実行することが可能になります。
- CUDAの統合: このツールキットはCUDAとも密接に統合されており、Dockerコンテナ内からCUDAライブラリにアクセスできます。これにより、CUDAを利用するアプリケーションの開発とデプロイメントが容易になります。
- 柔軟性とポータビリティ: コンテナを利用することで、異なるシステムや異なるCUDAバージョンにまたがって、アプリケーションを一貫して動作させることができます。これは、GPUの計算リソースを必要とするアプリケーションにとって特に重要です。
- 簡単なセットアップ: NVIDIAのコンテナツールキットを使うと、ユーザーはGPUドライバーをコンテナイメージに含める必要がなくなります。ホストシステム上でドライバーが適切にセットアップされていれば、コンテナはそれを使用できます。
- エンドツーエンドのGPUサポート: NVIDIAはDockerコンテナのための全体的なGPUサポートを提供しており、開発からデプロイメント、スケーリングまでのプロセスを支援します。
NVIDIAのコンテナツールキットを利用することで、GPUを活用したアプリケーションの開発とデプロイメントが大幅に容易になります。これにより、機械学習、データサイエンス、その他のGPU集約型のタスクを効率的に行えるようになることは間違いありません。

下記のGithubのページを参考に作業をします。
わかりやすくするために、適当なディレクトリを作成し、そこへ移動します。そのディレクトリでDockerfileとスクリプトを作成します。
mkdir vall
cd vall
sudo nano DockerfileDockerfileの記述内容は下記になります。改良に改良を加えてようやくできました。これで動作しました。
# PyTorch 公式の CUDA 11.8 対応イメージを使用
FROM pytorch/pytorch:latest
# タイムゾーンのプロンプトを無効にするための環境変数を設定
ENV DEBIAN_FRONTEND=noninteractive
# 必要なパッケージをインストール(FFmpegとgitを含む)
RUN apt-get update && \
apt-get install -y python3-pip ffmpeg git && \
pip3 install --upgrade pip
# PyTorch, torchvision, torchaudioをCUDA 11.8でインストール
RUN pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Gradioをアップグレード
RUN pip install --upgrade gradio
# 作業ディレクトリを設定
WORKDIR /usr/src/app
# VALL-E-X リポジトリをクローン
RUN git clone https://github.com/Plachtaa/VALL-E-X.git
# クローンしたリポジトリのディレクトリに作業ディレクトリを変更
WORKDIR /usr/src/app/VALL-E-X
# requirements.txtに指定されている必要なパッケージをインストール
RUN pip install --no-cache-dir -r requirements.txt
# 環境変数PATHにFFmpegを追加
ENV PATH="/usr/bin/ffmpeg:$PATH"
# ローカルの修正済み launch-ui.py をコンテナ内にコピー
COPY launch-ui.py .
# checkpoints と whisper フォルダを作成
RUN mkdir -p ./checkpoints
RUN mkdir -p ./whisper
# 環境変数を定義
ENV NAME World
# コンテナ起動時に launch-ui.py を実行
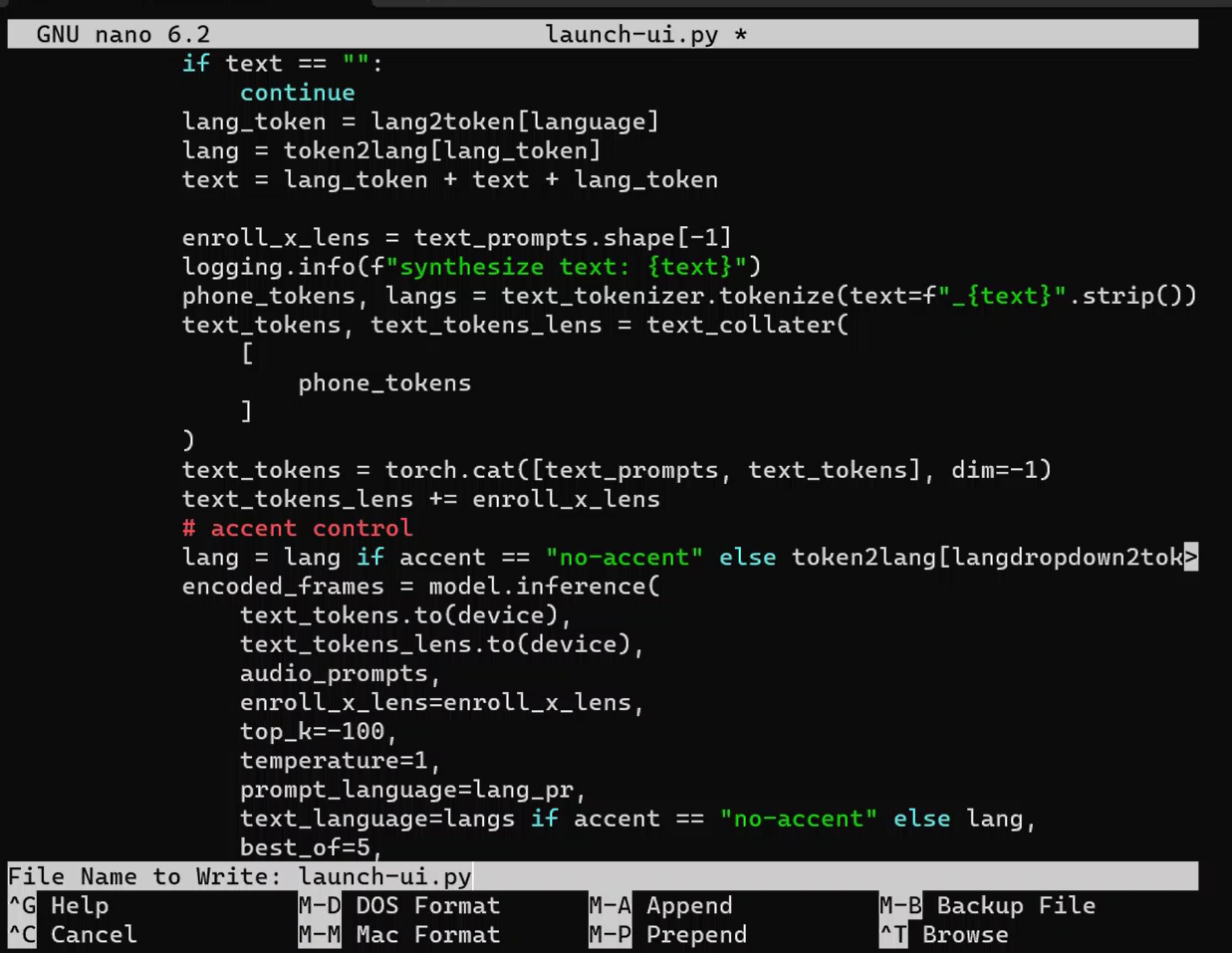
CMD ["python3", "launch-ui.py"]スクリプトは、Githubのlaunch-ui.pyを改変しました。Dockerfileと同じ場所に保存します。ローカル以外からのアクセスを許可する記述などが必要でした。ほかにも改変を少々。
sudo nano launch-ui.py長いので、以下のページでダウンロードできるようにしておきました。

Dockerfileをもとにビルドしてイメージを作成します。
docker build -t valle .作成されたイメージを使用してコンテナを立ち上げます。
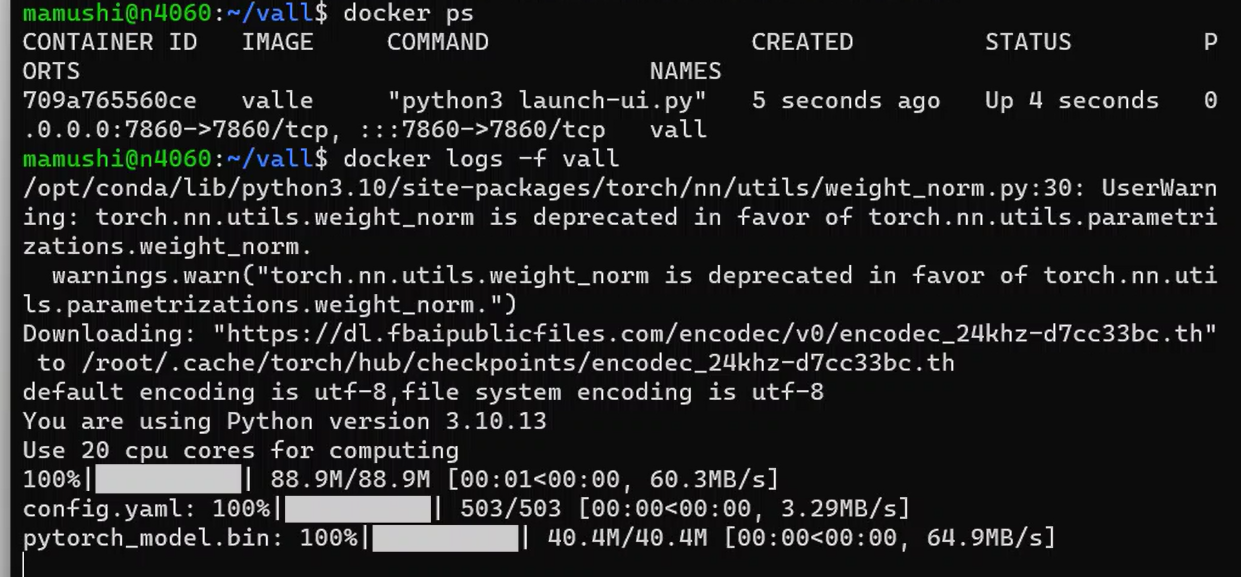
docker run -d --name vall --gpus all -p 7860:7860 valleここで注意すべき点があります。コンテナはすぐに立ち上がったかのようにみえます。しかし、すぐにブラウザでアクセスするとエラーになるかもしれません。モデルのダウンロードをしているからです。以下のコマンドで確認できます。
docker logs -f valldocker logs -f コンテナ名 コマンドは、Dockerで特定のコンテナのログをリアルタイムで表示するために使用されます。ここで各部分の意味を説明します。
- docker logs: このコマンドはDockerに対して、指定されたコンテナのログを取得するように指示します。コンテナが実行するアプリケーションやプロセスによって出力されるすべての標準出力(stdout)と標準エラー出力(stderr)が表示されます。
- -f: このオプションは “follow” の略で、ログをリアルタイムで追跡することを意味します。つまり、コンテナから新しいログが出力されると、それらがコマンドラインに即座に表示されます。これは、アプリケーションの現在の動作を監視するのに便利です。
- コンテナ名: これは、ログを表示したいDockerコンテナの名前です。Dockerでは、各コンテナには一意の名前が割り当てられています。この名前を指定することで、その特定のコンテナのログを表示できます。
簡単に言うと、docker logs -f コンテナ名 コマンドは、指定したDockerコンテナのログをリアルタイムで表示し、コンテナ内で何が起こっているかを監視するために使用されます。これはデバッグやシステムの監視に非常に有用です。
十分時間がたったらブラウザでアクセスします。WSLのIPアドレスはip aなどで確認できます。

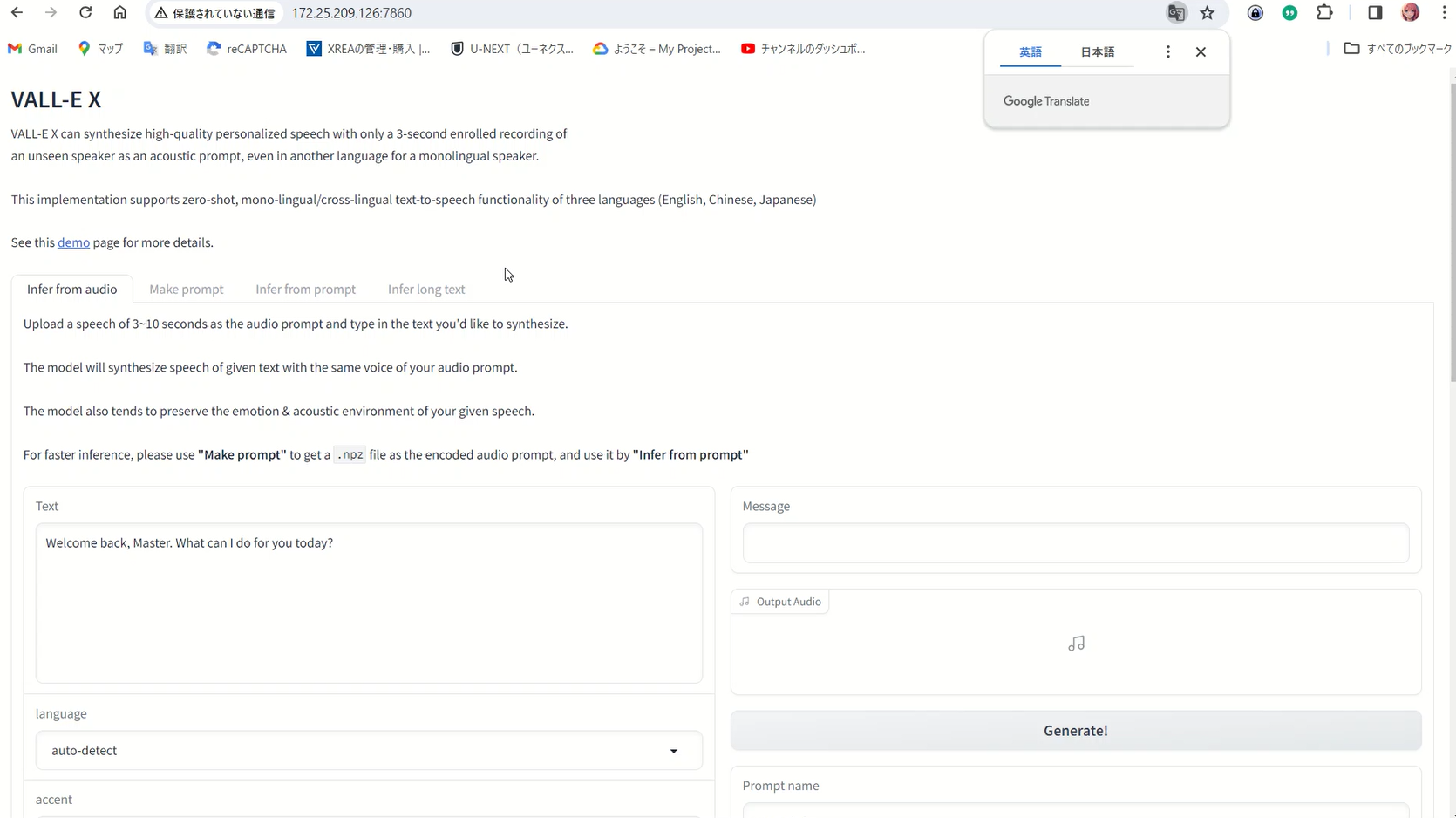
Windows Subsystem for Linux(WSL)で実行されている環境は、ホストのWindows環境とは異なるネットワーク設定を持っています。これにはいくつかの重要な点があります。
- プライベートIPアドレス: WSLは、通常、ホストのWindowsシステムとは異なるプライベートIPアドレスを割り当てられます。これは、WSLが独自のネットワークインターフェースを持ち、ホストOSとは別のサブネット上に存在するためです。
- ネットワーク分離: WSLが異なるIPアドレスを持つことは、ネットワーク的に分離されていることを意味します。そのため、WSL内で実行されているサービスやアプリケーションにアクセスするには、そのIPアドレスを使用する必要があります。
- 通信とポートフォワーディング: WSLとホストWindows間の通信は可能ですが、ポートフォワーディングや特定のネットワーク設定を適切に設定する必要がある場合があります。特に、WSL内で実行されるサーバーに外部からアクセスする場合には、これが重要になります。
- 開発環境の影響: Pythonなどの開発環境では、WSL上で実行されるプログラムとホストOS上で実行されるプログラム間でネットワークアクセスに関する違いを考慮する必要があります。これは、ローカル開発環境をセットアップする際に特に重要です。
WSLはWindows上でLinux環境を実行するための便利なツールですが、ネットワーク設定やIPアドレスの違いにより、特定の状況で追加の設定や調整が必要になることがあります。
コンテナ内でpythonのスクリプトを実行すると、次のメッセージが表示されます。コンテナに入るには以下のコマンドを入力します。
docker exec -ti vall bashroot@709a765560ce:/usr/src/app/VALL-E-X# python3 launch-ui.py default encoding is utf-8,file system encoding is utf-8 You are using Python version 3.10.13 Use 20 cpu cores for computing /opt/conda/lib/python3.10/site-packages/torch/nn/utils/weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm. warnings.warn(“torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.”) Running on local URL: http://0.0.0.0:7861 Running on public URL: https://a8d8a69c61a01967a3.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
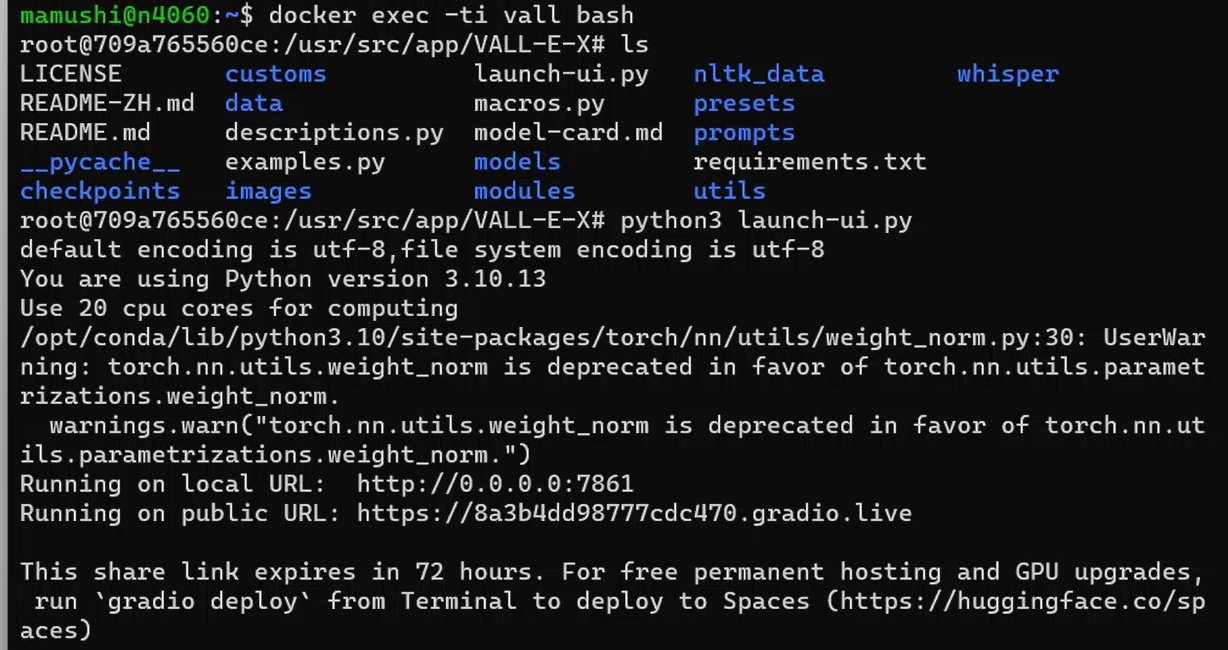
表示されたメッセージに基づくと、使用しているアプリケーション(おそらくGradioというツール)が一時的な公開URLを生成したことを意味しています。
具体的には、
- ローカルURL:
http://0.0.0.0:7861は、コンテナ内で実行されているアプリケーションにローカルネットワーク(つまり、同じネットワーク上の他のデバイスやコンピュータから)でアクセスするためのURLです。 - 公開URL:
https://a8d8a69c61a01967a3.gradio.liveは、インターネット上のどこからでもアクセスできる一時的な公開URLです。このURLは、Gradioサービスによって提供されており、アプリケーションを外部のユーザーと共有するための手段を提供します。 - 72時間の有効期限: この公開URLは72時間後に期限切れとなります。永続的なホスティングやGPUのアップグレードが必要な場合は、Hugging FaceのSpacesプラットフォームにデプロイすることを検討すると良いでしょう。
要約すると、表示されたメッセージは、コンテナ内で実行されているアプリケーションが一時的な公開URLを生成し、それを利用してインターネット上の任意の場所からアクセスできるようになったことを示しています。これは、Gradioや類似のツールを使用してアプリケーションを簡単に共有するための一般的な方法です。
パソコンの電源を切ったなどの理由で、次回以降にVALL-E Xを使用するには次のコマンドでコンテナを起動します。
docker start vall